Code
!pip install kaggleIntroduction: In this project, we explore how Artificial Intelligence (AI), powered by Deep Learning, can assist doctors in diagnosing pneumonia using chest X-ray images. Pneumonia is a severe infection that inflames the lungs and is a leading cause of illness worldwide. Early detection is critical, but in areas with limited access to radiologists, diagnosis can be challenging.
Convolutional Neural Networks (CNNs) are a type of deep learning model designed to analyze visual data, like images. These models learn to identify patterns in chest X-rays that indicate pneumonia, much like how a trained radiologist would.
How CNN Assists Doctors:
1. Image Analysis: CNNs process X-ray images and learn to detect subtle signs of pneumonia that may not be immediately visible to the human eye.
Speed and Scalability: AI models analyze hundreds or even thousands of X-rays in a fraction of the time it would take a human.
Second Opinion: The AI serves as a supportive tool, providing doctors with additional insights and increasing diagnostic confidence.
Accessible Diagnostics: In remote or underserved areas, AI can bridge the gap where expert radiologists are not readily available.
Why This Project Matters:
- Accuracy: CNNs can identify patterns that may be difficult for even experienced doctors to spot.
Life-Saving Potential: Faster diagnosis means quicker treatment, saving lives.
Global Impact: AI tools can bring advanced medical diagnostics to regions with limited resources, democratizing healthcare.
By the end of this project, you’ll understand how CNNs are built, trained, and deployed to analyze medical images and assist in critical healthcare decisions. Let’s start our journey into AI-powered healthcare!
!pip install kaggle# Install necessary Python packages
!pip install kaggle matplotlib pandas
!pip install --upgrade tensorflow
# Check installations
import tensorflow as tf
import matplotlib
import pandas
import kaggle
print("TensorFlow version:", tf.__version__)
print("Matplotlib version:", matplotlib.__version__)
print("Pandas version:", pandas.__version__)
print("Kaggle installed successfully.")!pip install tensorflow==2.17.0!pip install tf-keras==2.17.0import tensorflow as tf
print("TensorFlow version:", tf.__version__)TensorFlow version: 2.17.0!pip install matplotlib pandasimport matplotlib, pandas
print("TensorFlow version:", tf.__version__)
print("Matplotlib version:", matplotlib.__version__)
print("Pandas version:", pandas.__version__)
print("Kaggle installed successfully.")TensorFlow version: 2.17.0
Matplotlib version: 3.10.0
Pandas version: 2.2.2
Kaggle installed successfully.The Data: Sourcing and Preparing “To start with, we need data. Here, the Kaggle platform becomes our go-to. It’s like a vast online library where we can find datasets for training our model. We will use a dataset available on Kaggle for chest X-rays that includes cases with and without pneumonia. The Kaggle API is what helps us download this data directly into our workspace.
import os
from google.colab import files
# Upload kaggle.json
files.upload() # Use this to upload the kaggle.json file
# Set up Kaggle credentials
os.makedirs('/root/.kaggle', exist_ok=True)
!mv kaggle.json /root/.kaggle/
!chmod 600 /root/.kaggle/kaggle.jsonSaving kaggle.json to kaggle.jsonThis prepares our system to download the data. Remember, the Kaggle API acts like our supermarket for datasets.”
!ls -la /root/.kaggletotal 16
drwxr-xr-x 2 root root 4096 Jan 12 03:49 .
drwx------ 1 root root 4096 Jan 12 03:48 ..
-rw------- 1 root root 73 Jan 12 03:49 kaggle.jsonDownload and Extract the dataset then Verify the dataset structure
import zipfile
# Download the dataset
!kaggle datasets download -d paultimothymooney/chest-xray-pneumonia -p /content/
# Extract the dataset
with zipfile.ZipFile('/content/chest-xray-pneumonia.zip', 'r') as zip_ref:
zip_ref.extractall('/content/chest_xray')
# Verify the dataset structure
!ls -la /content/chest_xrayDataset URL: https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia
License(s): other
Downloading chest-xray-pneumonia.zip to /content
100% 2.29G/2.29G [00:29<00:00, 142MB/s]
100% 2.29G/2.29G [00:29<00:00, 82.7MB/s]
total 12
drwxr-xr-x 3 root root 4096 Jan 12 03:57 .
drwxr-xr-x 1 root root 4096 Jan 12 03:57 ..
drwxr-xr-x 7 root root 4096 Jan 12 03:58 chest_xrayPreparing Data for Training with Image Generators “Now that we have our dataset downloaded, let us move to the next crucial step—preparing our data. This is like preparing ingredients for a perfect recipe. The data must be preprocessed so that it is clean and uniform before it enters our CNN model. For this, we will use something called the ImageDataGenerator. This tool ensures that all the images are resized and normalized properly. Let me explain it with the code snippet below. Follow along carefully.”
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Define paths for train and test directories
train_dir = 'chest_xray/chest_xray/train'
test_dir = 'chest_xray/chest_xray/test'
# Define ImageDataGenerators
train_gen = ImageDataGenerator(rescale=1./255).flow_from_directory(
train_dir, target_size=(128, 128), batch_size=32, class_mode='binary'
)
test_gen = ImageDataGenerator(rescale=1./255).flow_from_directory(
test_dir, target_size=(128, 128), batch_size=32, class_mode='binary'
)Found 5216 images belonging to 2 classes.
Found 624 images belonging to 2 classes.Step-by-Step Explanation
1. Paths to Train and Test Data: “We first define the paths for the train and test datasets. These directories will contain the images for training and testing our model. we need to ensure the folder structure matches the specified paths, like this: - train: Images categorized into ‘pneumonia’ and ‘normal’ folders.
test: Similarly organized for testing.”Image Rescaling: “Now, notice rescale=1./255 in the code. This step normalizes the pixel values of the images. By dividing by 255, we map the pixel values from 0-255 to a 0-1 range. This makes it easier for the model to process the images.”
Target Image Size: “We set target_size=(128, 128), which resizes all images to 128x128 pixels. Why is this important? It ensures uniformity in dimensions, making it easier for our CNN model to analyze them.”
Batch Size: “Here, the batch_size=32 means the model processes 32 images at a time. This is like feeding the model bite-sized pieces of data, so it doesn’t get overwhelmed.”
Class Mode: “The class_mode='binary' tells the model that there are only two classes—‘pneumonia’ and ‘normal’. This binary classification simplifies the problem for the model.”
Data Generators: “We create two generators:
train_gen for training the model.
test_gen for testing its performance. These generators will automatically load and preprocess the images from the specified directories.”
With this step, we have successfully prepped our data for training. In the next section, we will dive into designing the architecture of our CNN model.
Building and Compiling the CNN Model “Now that we have our data prepared, we are ready to build the heart of our project—the Convolutional Neural Network (CNN) model. Think of this as crafting the brain of our AI, the part that will actually learn to detect pneumonia from chest X-ray images.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
# Build the CNN model
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(128, 128, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid') # Binary output: Pneumonia or Normal
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()/usr/local/lib/python3.10/dist-packages/keras/src/layers/convolutional/base_conv.py:107: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(activity_regularizer=activity_regularizer, **kwargs)Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩ │ conv2d (Conv2D) │ (None, 126, 126, 32) │ 896 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ max_pooling2d (MaxPooling2D) │ (None, 63, 63, 32) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ conv2d_1 (Conv2D) │ (None, 61, 61, 64) │ 18,496 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ max_pooling2d_1 (MaxPooling2D) │ (None, 30, 30, 64) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ flatten (Flatten) │ (None, 57600) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense (Dense) │ (None, 128) │ 7,372,928 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dropout (Dropout) │ (None, 128) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_1 (Dense) │ (None, 1) │ 129 │ └──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 7,392,449 (28.20 MB)
Trainable params: 7,392,449 (28.20 MB)
Non-trainable params: 0 (0.00 B)
Step-by-Step Explanation
1. Model Architecture - Sequential API: “We are using the Sequential API to build our model. This means we will stack layers one after the other, like building blocks. It’s straightforward and ideal for this task.”
Conv2D layer with 32 filters, a 3x3 kernel, and the ReLU activation function.What does this do? It helps extract features from the images, such as edges and textures.
The input_shape=(128, 128, 3) tells the model that our images are 128x128 pixels with 3 color channels (RGB).”
MaxPooling2D layer.This reduces the spatial size of the features, making the computation more efficient and preventing overfitting.
It’s like summarizing the important parts of the image and ignoring the noise.”
Flattening: “The Flatten() layer transforms the 2D feature maps into a 1D vector. This is required to feed the data into the dense layers that follow.”
Dense Layers: “Next, we add a Dense layer with 128 neurons and ReLU activation.
This is a fully connected layer that combines all the extracted features to make predictions.
We also include a Dropout layer with a rate of 0.5 to prevent overfitting by randomly turning off neurons during training.”
sigmoid activation function.Why sigmoid? Because it outputs a probability between 0 and 1, which is perfect for binary classification.
Here, 0 means ‘normal’ and 1 means ‘pneumonia.’”
Compiling the Model “Now that our architecture is ready, we need to compile the model. This is like setting the rules for how the model will learn.
The optimizer='adam' ensures that the model learns efficiently.
The loss='binary_crossentropy' measures how well the model is doing during training.
The metrics=['accuracy'] tracks the model’s performance, so we know how accurately it classifies X-rays.”
Model Summary When we run the code, the model.summary() function will display the architecture of our model, showing you the layers, the number of parameters, and their connectivity.
Input Shape: If our dataset has images of different sizes, adjust the input_shape accordingly.
Dropout Rate: If our model is overfitting, we may increase the dropout rate slightly. Conversely, if underfitting, we can reduce it.
Number of Neurons: we can experiment with the number of neurons in the dense layer (e.g., 256 instead of 128) to see if it improves accuracy.”
With this, our CNN model is ready for training. In the next lecture, we’ll feed our data into the model and watch it learn.
Training the Model Now, it’s time to train it. This is the moment where our AI will actually start learning!
# Train the model
history = model.fit(
train_gen,
epochs=10,
validation_data=test_gen
)Epoch 1/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 224s 1s/step - accuracy: 0.8154 - loss: 0.4809 - val_accuracy: 0.7356 - val_loss: 0.9140
Epoch 2/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 208s 1s/step - accuracy: 0.9581 - loss: 0.1188 - val_accuracy: 0.7692 - val_loss: 0.9967
Epoch 3/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 215s 1s/step - accuracy: 0.9631 - loss: 0.1050 - val_accuracy: 0.7163 - val_loss: 1.3252
Epoch 4/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 209s 1s/step - accuracy: 0.9748 - loss: 0.0821 - val_accuracy: 0.6955 - val_loss: 1.0352
Epoch 5/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 206s 1s/step - accuracy: 0.9702 - loss: 0.0753 - val_accuracy: 0.7484 - val_loss: 1.4450
Epoch 6/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 211s 1s/step - accuracy: 0.9791 - loss: 0.0577 - val_accuracy: 0.7724 - val_loss: 1.2698
Epoch 7/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 261s 1s/step - accuracy: 0.9792 - loss: 0.0484 - val_accuracy: 0.7276 - val_loss: 1.2304
Epoch 8/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 217s 1s/step - accuracy: 0.9811 - loss: 0.0446 - val_accuracy: 0.7228 - val_loss: 1.5039
Epoch 9/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 214s 1s/step - accuracy: 0.9856 - loss: 0.0383 - val_accuracy: 0.7340 - val_loss: 1.3406
Epoch 10/10
163/163 ━━━━━━━━━━━━━━━━━━━━ 268s 1s/step - accuracy: 0.9889 - loss: 0.0305 - val_accuracy: 0.7163 - val_loss: 2.3790/usr/local/lib/python3.10/dist-packages/keras/src/trainers/data_adapters/py_dataset_adapter.py:122: UserWarning: Your `PyDataset` class should call `super().__init__(**kwargs)` in its constructor. `**kwargs` can include `workers`, `use_multiprocessing`, `max_queue_size`. Do not pass these arguments to `fit()`, as they will be ignored.
self._warn_if_super_not_called()Explanation of the Training Process
1. The fit Method: “The model.fit() function is where the actual training happens. Here’s what each parameter means: - train_gen: This is our training dataset. The model will learn from this data.
epochs=10: The model will go through the training data 10 times. we can increase this if We want better accuracy, but remember, more epochs will also take more time.
validation_data=test_gen: This is the testing data. After each epoch, the model will evaluate itself on this dataset to see how well it is performing.”
Increasing epochs for better learning, but watch out for overfitting.
If training takes too long, try reducing the batch_size in the data generator or using a more powerful GPU.
Testing the Model with a Sample Image “Now comes the exciting part—testing our model on a sample image. Let us see how well it predicts pneumonia or normal lungs. Here’s the code for that.”
import numpy as np
from tensorflow.keras.preprocessing.image import load_img, img_to_array
import matplotlib.pyplot as plt
# Load a sample image from the test dataset
sample_image_path = 'chest_xray/chest_xray/test/NORMAL/NORMAL2-IM-0035-0001.jpeg'
sample_image = load_img(sample_image_path, target_size=(128, 128))
sample_image_array = img_to_array(sample_image) / 255.0
sample_image_array = np.expand_dims(sample_image_array, axis=0)
# Make a prediction
prediction = model.predict(sample_image_array)
# Display the image with the prediction
plt.imshow(sample_image)
plt.title(f"Prediction: {'Pneumonia' if prediction[0][0] > 0.5 else 'Normal'}")
plt.axis('off')
plt.show()1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 104ms/step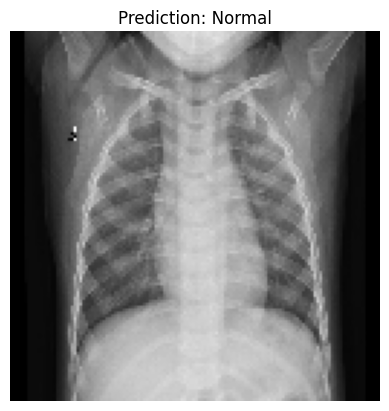
Step-by-Step Explanation
1. Loading the Image: “We first load a sample X-ray image using the load_img() function. Make sure the path to the image is correct. - The target_size=(128, 128) resizes the image to match the input size of our CNN.”
img_to_array(). Dividing by 255.0 normalizes the pixel values, just like we did for the training data.np.expand_dims() to make it compatible with the model input.”Making Predictions: “The model.predict() function generates a prediction. If the value is greater than 0.5, the model predicts ‘Pneumonia’; otherwise, it predicts ‘Normal’.”
Displaying the Image: “Finally, we use Matplotlib to display the image along with the prediction. Isn’t it satisfying to see our model in action?”
import numpy as np
from tensorflow.keras.preprocessing.image import load_img, img_to_array
import matplotlib.pyplot as plt
# Load a sample image from the test dataset
sample_image_path = 'chest_xray/chest_xray/test/PNEUMONIA/person100_bacteria_475.jpeg'
sample_image = load_img(sample_image_path, target_size=(128, 128))
sample_image_array = img_to_array(sample_image) / 255.0
sample_image_array = np.expand_dims(sample_image_array, axis=0)
# Make a prediction
prediction = model.predict(sample_image_array)
# Display the image with the prediction
plt.imshow(sample_image)
plt.title(f"Prediction: {'Pneumonia' if prediction[0][0] > 0.5 else 'Normal'}")
plt.axis('off')
plt.show()1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 95ms/step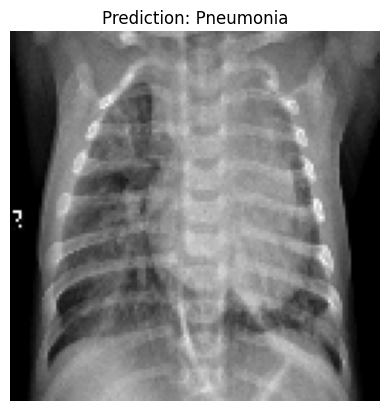
we have successfully trained and tested our CNN model for pneumonia detection.
Save the model, then make additional adjustments for the future.
# Save the model
model.save('/content/pneumonia_detection_model.h5')
# Verify the saved model
!ls -la /content/pneumonia_detection_model.h5WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. -rw-r--r-- 1 root root 88749784 Jan 12 05:15 /content/pneumonia_detection_model.h5